AI programming tools are experiencing explosive growth, with tools like Cursor, Claude Code, Aider, and Windsurf emerging rapidly. Developers are caught in the wave of Vibe Coding but face common challenges: while writing demos with AI is smooth, real projects often suffer from issues like stability, maintainability, and technical debt. Despite the increasing number of plugins and advanced models, problems such as AI code hallucinations, logical flaws, and context loss persist.
The root of the issue is that many developers remain stuck in the initial stage of coding with AI, relying solely on the tools without establishing a standardized development model suitable for the AI era. The evolution of AI programming has progressed from line-level code completion to modular and project-level delivery. If development thinking and work modes do not upgrade accordingly, even the most powerful AI tools will merely become temporary aids for code assembly.
Understanding Vibe Coding: Distinguishing Ambient Programming from Engineering Development
To establish a mature AI development model, it is crucial to understand the original definition of Vibe Coding and differentiate between effective AI development and blind adherence to ambient programming.
The term Vibe Coding was first introduced by Karpathy in 2025, meaning to follow intuition and atmosphere completely, using AI tools to accept code changes without careful reading of code differences, directly feeding error messages to the model, and circumventing unresolvable bugs without deep engagement in code logic. This mode prioritizes speed over manual review and engineering constraints, suitable for expert developers creating rapid prototypes. However, ordinary developers blindly copying this approach can introduce numerous hidden risks.
The concept of Vibe Engineering emerged to clearly differentiate from the original Vibe Coding. Pure Vibe Coding involves submitting code without reviewing differences or writing tests, making it impossible to explain code logic to a team. In contrast, Vibe Engineering retains the efficiency of AI while adhering to software development disciplines, ensuring requirement alignment, code reviews, testing validation, and architectural constraints, treating AI as a collaborative partner rather than a sole executor.
Many complaints about AI programming stem not from genuine AI-assisted development but from ordinary developers blindly following the unrestrained ambient programming model of experts. Experts possess strong code insight, quickly identifying and fixing AI vulnerabilities, while ordinary developers produce seemingly functional code that hides numerous logical flaws, leading to concentrated issues and increasing technical debt over time.
This underscores a core principle: the stronger the AI, the more humans must retain control. The underlying logic of mature AI development is not to let AI handle everything but to establish a reasonable division of labor, where AI manages tedious code implementation while humans control requirements, context boundaries, and code reviews—each of which is essential. Missing any link can lead to project failure.
Three Recognized Classic Development Models Supporting AI Programming
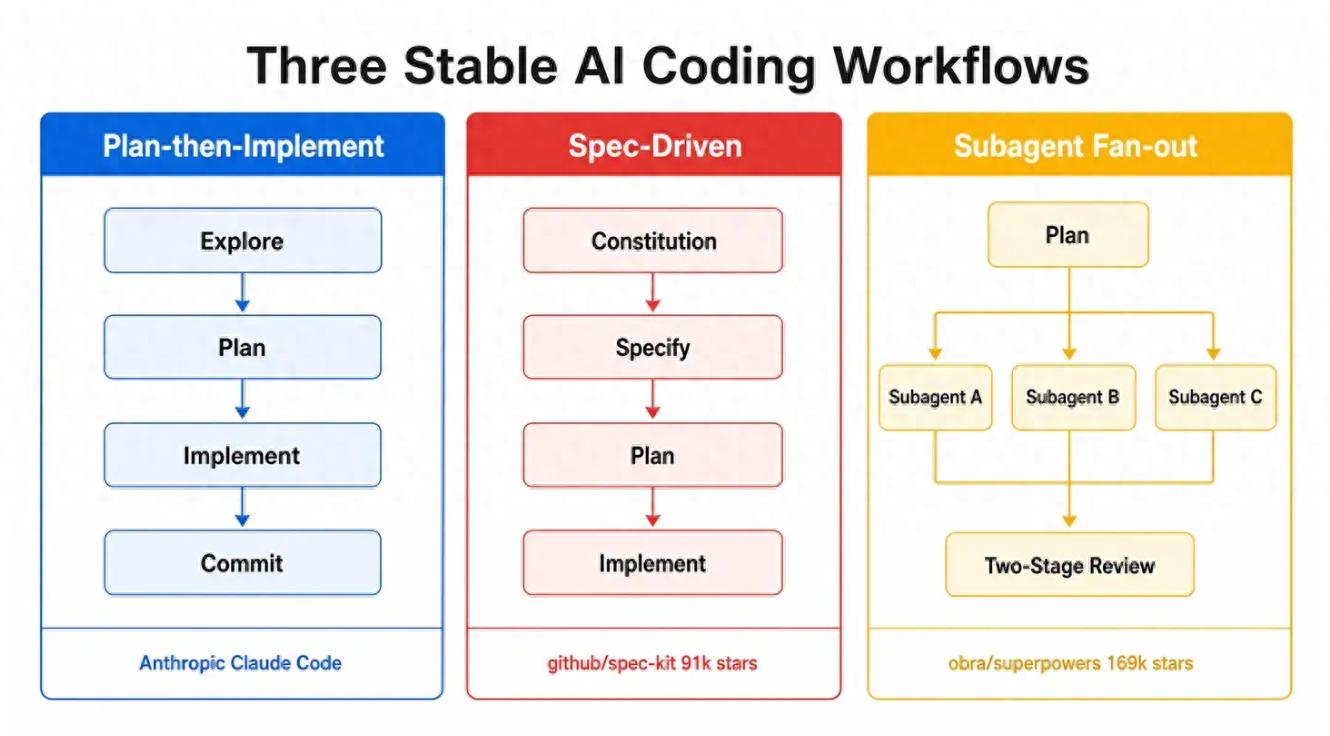
After more than two years of industry practice, three development models have consistently stood firm, serving as universal frameworks for large companies and experienced developers. These models address the core pain points of pre-planning, multi-agent consistency, and context degradation, and they can be used in combination without conflict.
The first model is the four-stage development model officially promoted by Anthropic: exploration, planning, implementation, and submission. This process separates thinking from execution, allowing the model to enter a read-only planning mode to review project code and architecture, clarifying existing business logic and technical constraints. A complete development plan document is produced, which is then manually reviewed and confirmed before switching to the regular mode for AI code development. The most crucial step after development is automated verification, which can include writing unit tests, performing interface screenshot comparisons, or validating output results through simple terminal commands.
Anthropic clearly states that automated self-verification is the most valuable leverage in AI development. Without a verification step, all bugs must be manually checked, wasting significant time and effort. By enabling AI to self-verify and repair, humans only need to review the final results, greatly reducing labor costs.
The second model is the Spec-Driven approach promoted by GitHub, which relies on the open-source project spec-kit to form a standardized process divided into four steps: specification formulation, requirement clarification, solution planning, and code implementation. The core innovation of this model is treating specification documents as code, allowing for versioned iterations and ensuring machine readability and human alignment.
This model is particularly advantageous in medium to large projects and team collaboration scenarios. A unified specification document can be distributed to multiple agents for parallel development, achieving high convergence in code logic and architectural design, preventing conflicts from independent writing. Natural language requirements are inherently vague, while specification documents transform ambiguous verbal requirements into structured, standardized technical agreements, reducing rework and misunderstandings from the outset.
The third model represents the parallel development of sub-agents, exemplified by the superpowers project, emphasizing a sub-driven development philosophy. Single agents have inherent limitations, such as a limited context window, which can lead to context pollution and gradual forgetting of earlier agreements during complex tasks.
The sub-agent model effectively addresses this issue. Once the overall development plan is established, complex tasks are broken down into multiple independent sub-tasks, each assigned to a dedicated sub-agent with its own context, allowing for independent development without interference. After completing all sub-tasks, two rounds of strict reviews are conducted: the first checks if the code meets the specification document requirements, and the second assesses code quality, performance, and compliance. Practical tests show that this model enables AI to develop continuously for hours without deviating from the plan, perfectly avoiding context overflow and memory loss issues associated with single agents.
Each of these models has its focus: the planning model safeguards the pre-thinking stage, the specification-driven model ensures cognitive consistency among multiple roles and agents, and the parallel sub-agent model addresses the limitations of single model context capabilities. However, they all maintain human decision-making authority, delegating only mechanical repetitive tasks to AI while adhering to the core principle of human-defined rules guiding AI execution.
Five Practical Engineering Development Models for Various Scenarios
In addition to the three foundational models, five practical sub-development models have emerged from the experiences of ByteDance, Alibaba, Google, and Microsoft, suitable for personal development, small projects, team collaboration, and enterprise-level platforms. Combining these models can create a complete and closed-loop AI development workflow.
Model One: Spec-First - Specification Before Code to Reduce Rework
A common misconception among AI programmers is to let the model write code directly, modifying it iteratively through fragmented conversations, akin to improvisational creation without structure. This chat-style development may suffice for simple demos, but in complex production systems, the rework rate can exceed 60%, with no guarantee of code quality or stability.
The Spec-First model overturns this logic, insisting on perfecting specification design before writing code. This shifts the human-machine alignment process from the coding phase to the specification phase, reducing costs significantly. Internal practice at ByteDance shows that direct AI code writing leads to a rework rate over 60%, while adopting the Spec-First model increases the first-pass success rate to over 70%, with a significant reduction in subsequent bugs.
A reusable three-layer specification model can be applied: the first layer defines functional specifications in natural language, outlining user stories and acceptance criteria, clarifying all scenarios and boundary conditions that the functionality must meet. The second layer is language-agnostic architectural specifications, defining data models, database table structures, interface routing designs, business state machines, and global security constraints, delineating the architectural framework without tying to specific programming languages. The third layer is language-specific implementation specifications, clarifying technology stack versions, framework choices, coding standards, testing frameworks, and error handling standards.
The practical implementation process is straightforward: first, describe core requirements in natural language, allowing AI to output a complete specification design document based on the three-layer model. After manual review and confirmation, AI can generate code in bulk based on this fixed specification, followed by automatically generating test cases for validation. Developers are encouraged to prepare a spec-prompt.md template for reuse, enhancing long-term efficiency.
Model Two: Layered Context Management to Address AI Memory Loss
Many developers encounter a common issue: as project scales increase, AI frequently forgets previously agreed architectural rules, repeatedly making similar mistakes or hallucinating nonexistent functions and files. Most believe this is due to model limitations, but the core bottleneck lies in context management. Google emphasizes that context is the core king of AI programming; the same model can yield vastly different results based on the quality of context provided.
Mature context management employs a layered strategy, dividing project information into three levels for precise injection. Level 0 (L0) is the global project layer, containing overall architecture, directory structure, technology stack choices, and coding standards, written in .cursorrules or CLAUDE.md files for permanent global effect. Level 1 (L1) is the module level, storing current development module interface definitions, dependencies, and module constraints, dynamically injected as needed. Level 2 (L2) is the task level, injecting only files, code, and test cases relevant to the current iteration, ensuring precise matching without redundancy.
Additionally, the CLAUDE.md management method recommended by Anthropic can be employed, creating a dedicated document in the project root directory to record project architecture, directory structure, commonly used terminal commands, historical pitfalls, and coding red lines. This eliminates the need to repeat basic project information in every conversation, as AI will automatically read the document in new sessions, maintaining cognitive consistency. Alibaba’s team has proven that effective layered context management can enhance the compatibility of AI-generated code with existing architecture from 40% to 85%, significantly reducing memory loss and hallucination issues.
Model Three: Guardrail Coding - Using Constraints Instead of Endless Instructions
Many people tend to use lengthy prompts to repeatedly instruct AI on how to write code, setting various positive requirements, but the results often fall short. Engineering practices from Microsoft and Google suggest a more efficient approach: instead of constantly telling AI what to do, clearly define what it cannot do, using comprehensive guardrails to limit AI’s operational boundaries. The more precise the constraints, the more reliable the output.
A three-layer guardrail system can be established, covering the entire development process. Hard guardrails are absolute red lines, such as prohibiting the arbitrary addition of third-party dependencies, disallowing unauthorized modifications to database table structures, forbidding the use of ‘any’ types in coding, and preventing the bypassing of exception handling. Soft guardrails are recommendations for code style and architectural norms, such as limiting function line counts, prioritizing composition over inheritance, standardizing error handling formats, and adhering to existing module coding styles. Guiding guardrails provide directional guidance, clarifying design priorities and marking compatibility requirements with external services, offering reference implementation examples.
During implementation, these three layers of guardrails can be written into .cursorrules for permanent effect. AI excels at filling in implementations under fixed constraints, and by clearly delineating red lines, there is no need for repeated instructions, allowing for automatic avoidance of most low-level errors and violations, proving to be much more efficient than endless verbal directives.
Model Four: Multi-Agent Pipeline - Specialization in Development Processes
Expecting a single AI to handle product requirements, architectural design, coding, development, testing, and review all at once contradicts the logic of professional specialization. A single agent with mixed roles is tasked with thinking about architecture, writing code, and conducting tests and reviews, leading to logical confusion and decreased output quality.
The multi-agent pipeline model centers on assigning specialized tasks to specialized agents, breaking the complete development process into multiple dedicated roles that connect into a standardized pipeline. A product agent interprets original requirements, producing structured requirement documents and acceptance criteria. An architecture agent formulates technical plans, interface definitions, and data models based on requirements and existing project architecture. A coding agent strictly develops business code according to the design plan. A testing agent automatically writes unit tests and integration tests, executing test cases to validate functionality. A review agent is responsible for examining code compliance, security vulnerabilities, and performance issues.
Each agent operates in an independent session with its own context, focusing solely on its responsibilities. The output from one role directly serves as input for the next, maintaining clear responsibilities and boundaries throughout the process. Even individual developers unable to access large company platforms can manually split conversations, allowing AI to assume one role at a time, significantly enhancing output quality. ByteDance’s internal DevFlow platform is based on this model, reducing the delivery cycle for moderately complex requirements from days to hours.
Model Five: Iterative Refinement Loop - Establishing a Generation-Verification-Repair Cycle
Many developers have overly high expectations of AI, hoping for it to produce perfect code in one go, and dismissing its value at the first sign of minor flaws. In reality, AI’s initial output typically scores around 70%, with basic logic intact but lacking details such as boundary condition handling and code standards. True experts do not seek perfection in one attempt; they establish a fixed iterative refinement loop to gradually enhance code quality.
This fixed loop process is simple and easy to implement. First, AI generates an initial version of the code, followed by automated verification, running lint checks for type validation and unit tests to capture all errors and warnings. The complete error log is then fed back to AI for targeted repairs. After repairs are complete, the process re-enters the verification phase, cycling until all checks pass, before finally entering the manual code review stage.
Anthropic’s Claude Code has deeply adapted to this model, allowing AI to automatically run tests and read error logs for self-repair. Shopify has integrated this logic into its CI pipeline, triggering AI to automatically repair and submit PRs after test failures, resolving over 30% of common issues without human intervention. Even ordinary developers can enhance code quality by over 40% by simply executing basic type checks like tsc --noEmit, avoiding reliance on manual code reviews and leveraging the advantages of automated validation.
Combining All Models to Build a Reusable AI Development Workflow
Using any single model addresses only specific issues. By linking and combining the five practical models, a complete, stable, and reusable standardized AI development workflow can be formed, adaptable to nearly all development scenarios.
The complete process follows a fixed order: first, enable the Spec-First model to clarify requirements and produce three layers of specification documents, manually reviewing and aligning before locking development goals. Next, employ layered context management to inject global, module-level, and task-level contexts, ensuring AI comprehensively understands project architecture and constraints. Then, activate guardrail coding to delineate development red lines, preventing violations. Following this, split tasks using the multi-agent pipeline, allowing roles to complete architectural design, coding, development, and testing. Finally, enter the iterative refinement loop, validating through automated testing, repeatedly repairing and optimizing, before conducting a final manual review and merging code for deployment.
This process is logically clear: first, clarify what to do through specification documents, then provide sufficient information through context management, delineate boundaries through guardrail rules, enhance professionalism through multi-role division, and finally polish stability through iterative cycles. Tools can be swapped at any time; Cursor, Claude Code, and Cline can all adapt, but the underlying logic of these foundational models remains universally applicable. Once mastered, developers can quickly and efficiently engage in development, regardless of how models and tools evolve.
Common Pitfalls in AI Programming: Avoiding the Invisible Traps of Ambient Programming
In implementing various development models, many developers fall into inherent misconceptions, wasting time and effort. Avoiding these pitfalls is essential to truly harnessing the value of AI.
First, do not treat AI as an advanced search engine. Many only ask AI for technical solutions and directly copy and paste code, which is the least efficient use. The core value of AI lies in its understanding of your project context, combining architectural constraints for customized development, rather than simply transporting generic code. Copying and pasting without context will only lead to architectural conflicts and logical mismatches.
Second, avoid arbitrary context pollution. Do not frequently switch tasks within the same session, such as writing backend interfaces, modifying frontend pages, and debugging database scripts. AI’s context window is limited, and frequent cross-domain switching can lead to mixed information, resulting in confused logic in subsequent outputs. It is advisable to open independent sessions for different modules and tasks to maintain context purity.
Third, abandon development methods without automated validation. Allowing AI to write code without running tests or validations is akin to driving with closed eyes; hidden bugs will accumulate. Even for small projects, basic type checks, syntax checks, and simple unit tests should be retained to establish a foundational validation loop.
Fourth, do not be overly reliant on an all-capable AI. No model can achieve professional standards across all roles, including product architecture, coding, testing, and security. Forcing a single AI to handle all tasks will result in subpar performance in every aspect. Learning to split roles and tasks is far more meaningful than pursuing model omnipotence.
Conclusion: Tools Evolve, but Models are the Lasting Core
From line-level completion to module-level delivery, and from single-person chat-style programming to multi-agent engineering collaboration, AI programming has moved past its primitive growth stage. Various plugins and tools are emerging, with rapid version updates, but tools are merely vehicles; what retains long-term value is the development models and engineering thinking refined through practical experience.
Vibe Coding should not remain at the level of casual ambient programming but evolve into an engineering-driven, efficient delivery method. Ordinary developers no longer need to blindly chase new tools or models, nor obsess over mystical prompt optimizations. By adhering to the core principles of human-machine division of labor, mastering the foundational three models and five practical models, and establishing their standardized workflows, they can completely escape the pitfalls of unstable AI code, excessive rework, and accumulated technical debt.
The future of software development will not see AI replacing programmers but rather programmers who master AI engineering development models replacing those who blindly follow ambient programming trends. By safeguarding the three core areas of human requirements, specifications, context, and review, and allowing AI to focus on implementation, we can navigate the correct path for long-term adaptation to the AI era.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.