Introduction
Claude has released an official report acknowledging a decline in the quality of Claude Code over the past month. The post-mortem analysis identified three main issues: the default reasoning effort was reduced from high to medium, a caching optimization bug led to forgetfulness, and overly lengthy system prompts degraded coding quality. All issues have been fixed in version v2.1.116+.
The problems were limited to Claude Code and the Agent SDK and did not affect the core model or API. The company has reset usage limits for all subscribers and plans to strengthen internal testing, evaluation systems, and progressive change processes.
Issues Identified
In the past month, we investigated user feedback regarding the decline in Claude’s response quality. We traced these reports back to three independent changes affecting Claude Code, Claude Agent SDK, and Claude Cowork. The API was not impacted.
As of April 20 (v2.1.116), all three issues have been resolved.
This article will explain what we discovered, what we fixed, and what changes we will implement to significantly reduce the likelihood of similar issues occurring again.
We take reports of performance or quality degradation very seriously. We never intentionally weaken model capabilities, and we confirmed immediately that the API and reasoning layers were unaffected.
Problem 1: Default Reasoning Effort Adjustment
On March 4, we adjusted the default reasoning effort for Claude Code from high to medium to reduce the long delays some users experienced in high mode, which made the UI appear frozen. This trade-off was a mistake. Users indicated they preferred a higher level of intelligence by default and only wanted to switch to lower effort for simpler tasks. Consequently, we rolled back this change on April 7. This issue affected Sonnet 4.6 and Opus 4.6.
Problem 2: Caching Optimization Bug
On March 26, we introduced a change to clear Claude’s earlier thinking content for sessions idle for over one hour, aimed at reducing delay when users re-entered the session. Due to a bug, this clearing action was triggered continuously in subsequent rounds of the session, causing Claude to appear forgetful and repetitive. We fixed this issue on April 10. This issue also affected Sonnet 4.6 and Opus 4.6.
Problem 3: System Prompt Length Limitation
On April 16, we added a directive to the system prompt to reduce verbosity. This, combined with other prompt changes, negatively impacted coding quality, leading us to roll it back on April 20. This issue affected Sonnet 4.6, Opus 4.6, and Opus 4.7.
These three changes affected different traffic slices and were implemented at different times, leading to an overall perception of widespread but inconsistent degradation. Although we began investigating these reports in early March, it was initially difficult to distinguish them from normal fluctuations in user feedback, and our internal usage and evaluations did not initially replicate the confirmed issues.
Default Reasoning Effort Adjustment Details
When we released Opus 4.6 in February, we set the default reasoning effort to high. Shortly after the release, we received user feedback indicating that Claude Opus 4.6 occasionally took too long in high effort mode, causing the UI to freeze and resulting in disproportionate delays and token consumption.
Generally, longer reasoning times yield better outputs. Claude Code allows users to set this trade-off with effort levels, balancing more thinking against lower latency and fewer usage limits. In calibrating the effort level, we consider this trade-off to select optimal points on the test-time-compute curve. We then decide which point to use as the default effort parameter sent to the Messages API, with other options available through /effort.
In internal evaluations, medium effort resulted in only slight declines in intelligence across most tasks while significantly reducing latency. It did not exhibit the same long-tail thinking delay issue and helped maximize user usage limits. Therefore, we made medium the default effort and explained the decision through in-product pop-ups.
Shortly after the change, users reported that Claude Code became less intelligent. We conducted multiple design iterations to clarify the current effort settings, reminding users they could modify the default value, including prompts, inline effort selectors, and reintroducing ultrathink, but most users retained the medium default setting.
After receiving more customer feedback, we reversed this decision on April 7. Now, all users default to xhigh effort when using Opus 4.7, while all other models default to high effort.
Caching Optimization Bug Details
When Claude reasons for a task, that reasoning is typically retained in the conversation history, allowing Claude to reference its previous edits and tool calls in subsequent rounds.
On March 26, we launched a change intended to enhance efficiency. We implemented prompt caching to make consecutive API calls cheaper and faster for users. When Claude initiates an API request, it writes the input tokens to the cache; after a period of inactivity, the prompt is evicted from the cache to free up space for other prompts. Cache utilization is a carefully managed metric, as detailed in our practices.
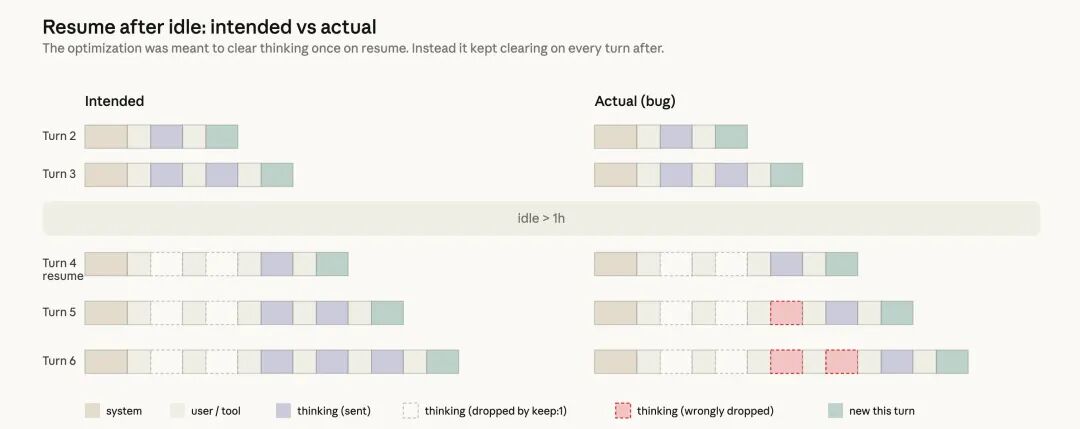
The design was straightforward: if a session had been idle for over one hour, we could clear the old thinking segments when users resumed the session to lower recovery costs. Since this request would also become a cache miss due to cache expiration, we could trim unnecessary messages from the request, reducing the number of uncached tokens sent to the API. We would then continue sending the complete reasoning history using the clear_thinking_20251015 API header along with keep:1.
However, a bug occurred. It did not clear the thinking history just once; instead, it continuously cleared it in every subsequent round of that session. This meant that once a session crossed the idle threshold, every request in that process would tell the API to retain only the most recent reasoning block, discarding all previous content. This issue compounded over time. If you sent a follow-up message while Claude was executing a tool call, this erroneous marking would initiate a new processing round, resulting in the loss of even the current round’s reasoning. Claude would continue executing but would increasingly forget why it chose its current actions. This ultimately manifested as forgetfulness, repetition, and odd tool choices reported by users.
Due to subsequent requests continuously discarding the thinking block, these requests also triggered cache misses. We believe this was another source of the independent issue, which was users reporting faster-than-expected usage limit consumption.
Two unrelated experiments made it initially harder for us to replicate this problem: one was a server-side experiment related to the message queue, enabled only internally; the other was an orthogonal change in how thinking was displayed, which masked this bug in most CLI sessions, so even when we tested external builds, we did not catch it in time.
This bug lay at the intersection of context management in Claude Code, the Anthropic API, and extended thinking. The changes involved passed multiple rounds of manual and automated code reviews, as well as unit tests, end-to-end testing, automated verification, and dogfooding. Additionally, it only occurred in a corner case—stale sessions—and replication was challenging, so it took us over a week to identify and confirm the root cause.
During the investigation, we performed a retrospective code review of the relevant PR with Opus 4.7. After providing sufficient context from the code repository, Opus 4.7 identified the bug, while Opus 4.6 did not. To prevent similar issues from occurring again, we are now enhancing code reviews to support more repository context.
We fixed this bug in v2.1.101 released on April 10.
System Prompt Length Limitation Details
Our latest model, Claude Opus 4.7, exhibits a notable behavioral characteristic: as mentioned during its release, it tends to be quite verbose. This can enhance its intelligence on complex issues but also results in more output tokens.
In the weeks leading up to the release of Opus 4.7, we began preparing for tuning Claude Code. Each model has subtle behavioral differences, and we spend time optimizing the corresponding harness and product-level behavior before each release.
We have various methods to reduce verbosity, including model training, prompt tuning, and improving the thinking UX within the product. Ultimately, we employed all these methods, but the addition of a new directive to the system prompt had an excessively negative impact on Claude Code’s intelligence performance:
“Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.”
After several weeks of internal testing, during which our set of evaluations did not reveal any degradation, we were confident in this change and released it with Opus 4.7 on April 16.
As part of this investigation, we conducted further ablation, removing each directive from the system prompt line by line to understand the specific impact of each, and we used a broader set of evaluations. One evaluation showed that both Opus 4.6 and 4.7 declined by 3%. Therefore, we immediately rolled back this prompt when we released on April 20.
Future Improvements
To prevent these issues from recurring, we will implement several changes: ensuring a larger proportion of internal staff use the exact same Claude Code builds as the public, rather than internal versions for testing new features; we will also improve our internal code review tools and provide the enhanced versions to customers.
We are also increasing the controls over changes to the system prompt. From now on, every change to Claude Code’s system prompt will undergo a broader, model-specific evaluation; we will continue to perform ablation to understand the impact of each line; and we have built new tools to facilitate easier review and auditing of prompt changes. Additionally, we have added guidance in CLAUDE.md to ensure that changes relevant to specific models are limited to the corresponding models. For any changes that may sacrifice intelligence performance, we will increase the soak period, expand the evaluation set, and adopt a progressive rollout to detect issues earlier.
We recently created @ClaudeDevs on X to provide more space to explain product decisions and the reasoning behind them. We will also synchronize the same updates in a centralized discussion thread on GitHub.
Finally, we want to thank all users. Whether through submitting issues via the /feedback command or posting specific and reproducible cases online, it is this feedback that ultimately allowed us to identify and fix these issues. Today, we are resetting usage limits for all subscribed users.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.